



For any businesses in the modern economy, information
used in corporate IT systems in the form of digital data has become a critical
intangible asset for their growth, sustainability, and competitiveness. Such
information includes intellectual property, customer data, company’s financials
and trade secrets, PII (Personally Identifiable Information) and PHI (Protected
Health Information) of clients and employees, technology “know-how”,
competitive intelligence, and many more types of meaningful knowledge. Data is
very much “the blood” of corporate IT, and as a loss of blood is deadly
dangerous for living organisms, so it is for businesses with leaks of data from
the corporate environment and its users.
Data breach has been one of the biggest fears that
organizations face today. Data Loss Prevention (DLP), first hit the market in
2006 and gained some popularity in early part of 2007. Just as we have
witnessed the growth of firewalls, intrusion detection systems (IDS) and
numerous security products, DLP has already improved considerably and is beginning
to influence the security industry.
Data loss prevention
(DLP) is a strategy for making sure that end users do not send sensitive or
critical information outside the corporate network. The term is also used to
describe software products that help a network administrator control what data
end users can transfer. DLP is typically defined as any solution or process
that identifies confidential data, tracks that data as it moves through and out
of the enterprise and prevents unauthorized disclosure of data by creating and
enforcing disclosure policies.
Data loss prevention
(DLP), per Gartner, may be defined as technologies which perform both content
inspection and contextual analysis of data sent via messaging applications such
as email and instant messaging, in motion over the network, in use on a managed
endpoint device, and at rest in on-premises file servers or in cloud
applications and cloud storage. These solutions execute responses based on
policy and rules defined to address the risk of inadvertent or accidental
leaks, or exposure of sensitive data outside authorized channels.
DLP solutions protect sensitive data
and provide insight into the use of content within the enterprise. Few enterprises
classify data beyond that which is public, and everything else. DLP helps
organizations better understand their data and improved their ability to
classify and manage content.
Since confidential data can reside on
a variety of computing devices (physical servers, virtual servers, databases,
file servers, PCs, point-of-sale devices, flash drives and mobile devices) and
move through a variety of network access points (wireline, wireless, VPNs,
etc.), there are a variety of solutions that are tackling the problem of data
loss, data recovery and data leaks. As the number of internet-connected devices
skyrockets into the billions, data loss prevention is an increasingly important
part of any organization’s ability to manage and protect critical and
confidential information. Examples of critical and confidential data types
include:
- Intellectual Property: source code, product design documents, process documentation, internal price lists
- Corporate Data: Financial documents, strategic planning documents, due diligence research for mergers and acquisitions, employee information
- Customer Data: Social Security numbers, credit card numbers, medical records, financial statements
DLP Features vs. DLP Solutions
The DLP
market is also split between DLP as a feature, and DLP as a solution. A number
of products, particularly email security solutions, provide basic DLP
functions, but aren't complete DLP solutions. The difference is:
•
A DLP Product includes centralized management, policy creation, and enforcement
workflow, dedicated to the monitoring and protection of content and data. The
user interface and functionality are dedicated to solving the business and
technical problems of protecting content through content awareness.
•
DLP Features include some of the detection and enforcement capabilities of DLP
products, but are not dedicated to the task of protecting content and data.
This
distinction is important because DLP products solve a specific business problem
that may or may not be managed by the same business unit or administrator
responsible for other security functions. We often see non-technical users such
as legal or compliance officers responsible for the protection of content. Even
human resources is often involved with the disposition of DLP alerts. Some
organizations find that the DLP policies themselves are highly sensitive or
need to be managed by business unit leaders outside of security, which also may
argue for a dedicated solution. Because DLP is dedicated to a clear business
problem (protect my content) that is differentiated from other security
problems (protect my PC or protect my network) most of you should look for
dedicated DLP solutions.
The last
thing to remember about DLP is that it is highly effective against bad business
processes (FTP exchange of unencrypted medical records with your insurance
company, for example) and mistakes. While DLP offers some protection against
malicious activity, we're at least a few years away from these tools protecting
against knowledgeable attackers.
How DLP works: Standalone vs. integrated
DLP products are designed to detect sensitive information as it is accessed by endpoint devices like desktops and mobile devices, as it lies dormant on a file server in forgotten documents, and as it moves through an organization's networks using any number of protocols. DLP tools address the problems of sensitive data usage, movement and storage based on an organization's understanding of what it wants to protect and where the data is allowed at any moment.
Standalone
DLP products can reside on specialized appliances or can be sold as software to
be installed on the enterprise's own hardware. They are specialized and only
address data loss prevention. A full soup-to-nuts DLP product monitors data at
rest using a file scanning engine. It also features a network appliance to
monitor data in transit over a company’s network on many network protocols.
An
endpoint agent detects sensitive information in memory, during printing
attempts, copying to portable media or exiting through network protocols. The
agents may also be able to detect sensitive information at rest by scanning
files found on endpoint logical drives.
Standalone DLP products also provide some manner of management
console, a report generator, a policy manager, a database to store significant
events and a quarantine server or folder to store captured sensitive data.
There is also usually a method to build custom detection policies.Integrated DLP features, by contrast to standalone DLP, are usually found on perimeter security gateways such as Web or email security gateways, intrusion detection systems/intrusion prevention systems, endpoint security suites and unified threat management products. Depending on their main functions, these products are most useful at detecting sensitive data in motion and sensitive data in use. Vulnerability scanners, for example, usually have DLP plug-ins to detect sensitive data at rest, such as Social Security numbers.
Unlike the convenience of having a standalone DLP product, security products with integrated DLP from different vendors do not share the same management consoles, policy management engines and data storage. That means an organization's DLP capability may end up being scattered among several different types of security products. Quarantine functions, if they exist, are handled through different management interfaces as well. Any attempt to correlate DLP events will have to be handled through a security information management (SIEM) system or a separate data correlation engine.
Content vs. Context
We
need to distinguish content from context. One of the defining characteristics
of DLP solutions is their content awareness. This is the ability of
products to analyze deep content using a variety of techniques, and is very
different from analyzing context. It's easiest to think of content as a letter,
and context as the envelope and environment around it. Context includes things
like source, destination, size, recipients, sender, header information,
metadata, time, format, and anything else short of the content of the letter
itself. Context is highly useful and any DLP solution should include contextual
analysis as part of an overall solution.
A
more advanced version of contextual analysis is business context analysis, which
involves deeper analysis of the content, its environment at the time of
analysis, and the use of the content at that time.
Content Analysis
The
first step in content analysis is capturing the envelope and opening it. The
engine then needs to parse the context (we'll need that for the analysis) and
dig into it. For a plain text email this is easy, but when you want to look
inside binary files it gets a little more complicated. All DLP solutions solve
this using file cracking. File cracking is the technology used to read
and understand the file, even if the content is buried multiple levels down.
For example, it's not unusual for the cracker to read an Excel spreadsheet
embedded in a Word file that's zipped. The product needs to unzip the file,
read the Word doc, analyze it, find the Excel data, read that, and analyze it. Some tools support analysis of encrypted data if enterprise
encryption is used with recovery keys, and most tools can identify standard
encryption and use that as a contextual rule to block/quarantine content.
Content Analysis Techniques
Once the content is accessed, there are seven major analysis techniques used to
find policy violations, each with its own strengths and weaknesses.
1. Rule-Based/Regular
Expressions: This is the
most common analysis technique available in both DLP products and other tools
with DLP features. It analyzes the content for specific rules — such as 16
digit numbers that meet credit card checksum requirements, medical billing
codes, or other textual analyses. Most DLP solutions enhance basic regular
expressions with their own additional analysis rules (e.g., a name in
proximity to an address near a credit card number).
What it's best for: As a first-pass filter, or for
detecting easily identified pieces of structured data like credit card numbers,
social security numbers, and healthcare codes/records.
Strengths: Rules
process quickly and can be easily configured. Most products ship with initial
rule sets. The technology is well understood and easy to incorporate into a
variety of products.
Weaknesses: Prone to
high false positive rates. Offers very little protection for unstructured
content like sensitive intellectual property.
2. Database Fingerprinting: Sometimes
called Exact Data Matching. This technique takes either a database dump or live
data (via ODBC connection) from a database and only looks for exact matches.
For example, you could generate a policy to look only for credit card numbers
in your customer base, thus ignoring your own employees buying online. More advanced
tools look for combinations of information, such as the magic combination of
first name or initial, with last name, with credit card or social security
number that triggers a California SB 1386 (California
S.B. 1386 was a bill passed by the California
legislature that amended civil codes 1798.29, 1798.82 and 1798.84, the
California law regulating the privacy of personal information)
disclosure. Make sure you understand the performance and security implications
of nightly extracts vs. live database connections.
What it's
best for: Structured data from databases.
Strengths: Very low
false positives (close to 0). Allows you to protect customer/sensitive data
while ignoring other, similar, data used by employees (like their personal
credit cards for online orders).
Weaknesses: Nightly
dumps won't contain transaction data since the last extract. Live connections
can affect database performance. Large databases affect product performance.
3. Exact File Matching: With this technique you take a hash of
a file and monitor for any files that match that exact fingerprint. Some
consider this to be a contextual analysis technique since the file contents
themselves are not analyzed.
What it's
best for: Media files
and other binaries where textual analysis isn't necessarily possible.
Strengths: Works on
any file type, low false positives with a large enough hash value (effectively
none).
Weaknesses: Trivial to
evade. Worthless for content that's edited, such as standard office documents
and edited media files.
4. Partial Document Matching: This technique looks for a complete or
partial match on protected content. Thus you could build a policy to protect a
sensitive document, and the DLP solution will look for either the complete text
of the document, or even excerpts as small as a few sentences. For example, you
could load up a business plan for a new product and the DLP solution would
alert if an employee pasted a single paragraph into an Instant Message. Most solutions
are based on a technique known as cyclical hashing, where you take a hash of a
portion of the content, offset a predetermined number of characters, then take
another hash, and keep going until the document is completely loaded as a
series of overlapping hash values. Outbound content is run through the same
hash technique, and the hash values compared for matches. Many products use
cyclical hashing as a base, then add more advanced linguistic analysis.
What it's best for: Protecting sensitive documents, or
similar content with text such as CAD files (with text labels) and source code.
Unstructured content that's known to be sensitive.
Strengths: Ability to
protect unstructured data. Generally low false positives (some vendors will say
zero false positives, but any common sentence/text in a protected document can
trigger alerts). Doesn't rely on complete matching of large documents; can find
policy violations on even a partial match.
Weaknesses: Performance limitations on the total
volume of content that can be protected. Common phrases/verbiage in a protected
document may trigger false positives. Must know exactly which documents you
want to protect. Trivial to avoid (ROT 1 encryption is sufficient for evasion).
5. Statistical Analysis: Use of machine learning, Bayesian
analysis, and other statistical techniques to analyze a corpus of content and
find policy violations in content that resembles the protected content. This
category includes a wide range of statistical techniques which vary greatly in
implementation and effectiveness. Some techniques are very similar to those
used to block spam.
What it's best for: Unstructured content where a deterministic technique, like partial
document matching, would be ineffective. For example, a repository of
engineering plans that's impractical to load for partial document matching due
to high volatility or massive volume.
Strengths: Can work
with more nebulous content where you may not be able to isolate exact documents
for matching. Can enforce policies such as "alert on anything outbound
that resembles the documents in this directory".
Weaknesses: Prone to false positives and false negatives. Requires a large
corpus of source content — the bigger the better.
6. Conceptual/Lexicon: This technique uses a combination of dictionaries,
rules, and other analyses to protect nebulous content that resembles an
"idea". It's easier to give an example — a policy that alerts on
traffic that resembles insider trading, which uses key phrases, word counts,
and positions to find violations. Other examples are sexual harassment, running
a private business from a work account, and job hunting.
What it's best for: Completely
unstructured ideas that defy simple categorization based on matching known
documents, databases, or other registered sources.
Strengths: Not all
corporate policies or content can be described using specific examples;
Conceptual analysis can find loosely defined policy violations other techniques
can't even think of monitoring for.
Weaknesses: In most
cases these are not user-definable and the rule sets must be built by the DLP
vendor with significant effort (costing more). Because of the loose nature of
the rules, this technique is very prone to false positives and false negatives.
7. Categories: Pre-built categories with rules and
dictionaries for common types of sensitive data, such as credit card numbers/PCI
protection, HIPAA, etc.
What it's best for: Anything that neatly fits a provided category. Typically easy to
describe content related to privacy, regulations, or industry-specific
guidelines.
Strengths: Extremely simple to configure. Saves significant policy generation
time. Category policies can form the basis for more advanced, enterprise
specific policies. For many organizations, categories can meet a large
percentage of their data protection needs.
Weaknesses: One size fits all might not work. Only good for easily categorized
rules and content.
These 7
techniques form the basis for most of the DLP products on the market. Not all
products include all techniques, and there can be significant differences
between implementations. Most products can also chain techniques — building complex
policies from combinations of content and contextual analysis techniques.
Protecting Data in Motion, At Rest, and In Use
The goal of DLP is to
protect content throughout its lifecycle. In terms of DLP, this includes three
major aspects:
• Data
at Rest: includes scanning of storage and other content repositories to
identify where sensitive content is located. We call this content discovery.
For example, you can use a DLP product to scan your servers and identify
documents with credit card numbers. If the server isn't authorized for that
kind of data, the file can be encrypted or removed, or a warning sent to the
file owner.
• Data
in Motion: is sniffing of traffic on the network (passively or inline via
proxy) to identify content being sent across specific communications channels.
For example, this includes sniffing emails, instant messages, and web traffic
for snippets of sensitive source code. In motion tools can often block based on
central policies, depending on the type of traffic.
• Data
in Use: is typically addressed by endpoint solutions that monitor data as the
user interacts with it. For example, they can identify when you attempt to
transfer a sensitive document to a USB drive and block it (as opposed to
blocking use of the USB drive entirely). Data in use tools can also detect
things like copy and paste, or use of sensitive data in an unapproved
application (such as someone attempting to encrypt data to sneak it past the
sensors).
Data in Motion
Many organizations first
enter the world of DLP with network based products that provide broad
protection for managed and unmanaged systems. It’s typically easier to start a
deployment with network products to gain broad coverage quickly. Early products
limited themselves to basic monitoring and alerting, but all current products
include advanced capabilities to integrate with existing network infrastructure
and provide protective, not just detective, controls.
Network Monitor

At
the heart of most DLP solutions lies a passive network monitor. The network
monitoring component is typically deployed at or near the gateway on a SPAN
port (or a similar tap). It performs full packet capture, session
reconstruction, and content analysis in real time. Performance is more complex
and subtle than vendors normally discuss. You might have to choose between
pre-filtering (and thus missing non-standard traffic) or buying more boxes and
load balancing. Also, some products lock monitoring into pre-defined port and
protocol combinations, rather than using service/channel identification based
on packet content. Even if full application channel identification is included,
you want to make sure it's enabled. Otherwise, you might miss non-standard
communications such as connecting over an unusual port. Most of the network
monitors are dedicated general-purpose server hardware with DLP software
installed. A few vendors deploy true specialized appliances. While some
products have their management, workflow, and reporting built into the network
monitor, this is often offloaded to a separate server or appliance.
Email Integration
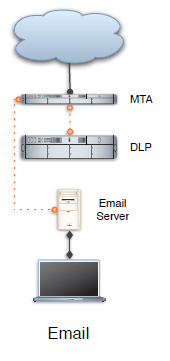
The
next major component is email integration. Since email is store and forward you
can gain a lot of capabilities, including quarantine, encryption integration,
and filtering, without the same hurdles to avoid blocking synchronous traffic.
Most products embed an MTA (Mail Transport Agent) into the product, allowing
you to just add it as another hop in the email chain. Quite a few also integrate
with some of the major existing MTAs/email security solutions directly for
better performance. One weakness of this approach is it doesn't give you access
to internal email. If you're on an Exchange server, internal messages never
make it through the external MTA since there's no reason to send that traffic
out. To monitor internal mail you'll need direct Exchange/Lotus integration,
which is surprisingly rare in the market. Full integration is different from
just scanning logs/libraries after the fact, which is what some companies call
internal mail support. Good email integration is absolutely critical if you
ever want to do any filtering, as opposed to just monitoring.
Filtering/Blocking and Proxy Integration
Nearly anyone deploying a
DLP solution will eventually want to start blocking traffic. There's only so
long you can take watching all your juicy sensitive data running to the nether
regions of the Internet before you start taking some action. But blocking isn't
the easiest thing in the world, especially since we're trying to allow good
traffic, only block bad traffic, and make the decision using real-time content
analysis. Email, as we just mentioned, is fairly straightforward to filter.
It's not quite real-time and is proxied by its very nature. Adding one more
analysis hop is a manageable problem in even the most complex environments.
Outside of email most of our communications traffic is synchronous — everything
runs in real time. Thus if we want to filter it we either need to bridge the
traffic, proxy it, or poison it from the outside.
Bridge
With a bridge we just have a
system with two network cards which performs content analysis in the middle. If
we see something bad, the bridge breaks the connection for that session.
Bridging isn't the best approach for DLP since it might not stop all the bad
traffic before it leaks out. It's like sitting in a doorway watching everything
go past with a magnifying glass; by the time you get enough traffic to make an
intelligent decision, you may have missed the really good stuff. Very few
products take this approach, although it does have the advantage of being
protocol agnostic.
Proxy
In simplified terms, a proxy is
protocol/application specific and queues up traffic before passing it on,
allowing for deeper analysis. We see gateway proxies mostly for HTTP, FTP, and
IM protocols. Few DLP solutions include their own proxies; they tend to
integrate with existing gateway/proxy vendors since most customers prefer
integration with these existing tools. Integration for web gateways is
typically through the iCAP protocol, allowing the proxy to grab the traffic,
send it to the DLP product for analysis, and cut communications if there's a
violation. This means you don't have to add another piece of hardware in front
of your network traffic and the DLP vendors can avoid the difficulties of
building dedicated network hardware for inline analysis. If the gateway includes
a reverse SSL proxy you can also sniff SSL connections. You will need to make changes
on your endpoints to deal with all the certificate alerts, but you can now peer
into encrypted traffic. For Instant Messaging you'll need an IM proxy and a DLP
product that specifically supports whatever IM protocol you're using.
TCP
Poisoning
The last method of filtering is
TCP poisoning. You monitor the traffic and when you see something bad, you
inject a TCP reset packet to kill the connection. This works on every TCP
protocol but isn't very efficient. For one thing, some protocols will keep
trying to get the traffic through. If you TCP poison a single email message,
the server will keep trying to send it for 3 days, as often as every 15
minutes. The other problem is the same as bridging — since you don't queue the
traffic at all, by the time you notice something bad it might be too late. It's
a good stop-gap to cover nonstandard protocols, but you'll want to proxy as
much as possible.
Internal Networks
Although technically
capable of monitoring internal networks, DLP is rarely used on internal traffic
other than email. Gateways provide convenient choke points; internal monitoring
is a daunting prospect from cost, performance, and policy management/false
positive standpoints. A few DLP vendors have partnerships for internal
monitoring but this is a lower priority feature for most organizations.
Distributed and Hierarchical Deployments
All medium to large
enterprises, and many smaller organizations, have multiple locations and web
gateways. A DLP solution should support multiple monitoring points, including a
mix of passive network monitoring, proxy points, email servers, and remote
locations. While processing/analysis can be offloaded to remote enforcement
points, they should send all events back to a central management
server for workflow, reporting, investigations, and archiving. Remote offices
are usually easy to support since you can just push policies down and reporting
back, but not every product has this capability. The more advanced products
support hierarchical deployments for organizations that want to manage DLP
differently in multiple geographic locations, or by business unit.
International companies often need this to meet legal monitoring requirements
which vary by country. Hierarchical management supports coordinated local
policies and enforcement in different regions, running on their own management
servers, communicating back to a central management server. Early products only
supported one management server but now we have options to deal with these
distributed situations, with a mix of corporate/regional/business unit
policies, reporting, and workflow.
Data at Rest
While catching leaks on
the network is fairly powerful, it's only one small part of the problem. Many
customers are finding that it's just as valuable, if not more valuable, to
figure out where all that data is stored in the first place. We call this content
discovery. The biggest advantage of content discovery in a DLP tool is that
it allows you to take a single policy and apply it across data no matter where
it's stored, how it's shared, or how it's used. For example, you can define a
policy that requires credit card numbers to only be emailed when encrypted,
never be shared via HTTP or HTTPS, only be stored on approved servers, and only
be stored on workstations/laptops by employees on the accounting team. All of
this can be specified in a single policy on the DLP management server.
Content discovery consists
of three components:
1. Endpoint
Discovery: scanning workstations and laptops for content.
2. Storage
Discovery: scanning mass storage, including file servers, SAN, and NAS.
3. Server
Discovery: application-specific scanning of stored data on email servers,
document management systems, and databases (not currently a feature of most DLP
products, but beginning to appear in some Database Activity Monitoring
products).
Content Discovery Techniques
There are three basic
techniques for content discovery:
1. Remote
Scanning: a connection is made to the server or device using a file sharing
or application protocol, and scanning is performed remotely. This is
essentially mounting a remote drive and scanning it from a server that takes policies
from, and sends results to, the central policy server. For some vendors this is
an appliance, for others it's a commodity server, and for smaller deployments
it's integrated into the central management server.
2. Agent-Based
Scanning: an agent is installed on the system (server) to be scanned and
scanning is performed locally. Agents are platform specific, and use local CPU
cycles, but can potentially perform significantly faster than remote scanning,
especially for large repositories. For endpoints, this should be a feature of
the same agent used for enforcing Data in Use controls.
3. Memory-Resident
Agent Scanning: Rather than deploying a full-time agent, a
memory-resident agent is installed, performs a scan, then exits without leaving
anything running or stored on the local system. This offers the performance of
agent-based scanning in situations where you don't want an agent running all
the time.
Any of these technologies can work for
any of the modes, and enterprises will typically deploy a mix depending on
policy and infrastructure requirements. We currently see technology limitations
with each approach which guide deployment:
• Remote
scanning can significantly increase network traffic and has performance
limitations based on network bandwidth and target and scanner network
performance. Some solutions can only scan gigabytes per day (sometimes hundreds,
but not terabytes per day), per server based on these practical limitations,
which may be inadequate for very large storage.
• Agents,
temporal or permanent, are limited by processing power and memory on the target
system, which often translates to restrictions on the number of policies that
can be enforced, and the types of content analysis that can be used. For
example, most endpoint agents are not capable of partial document matching or
database fingerprinting against large data sets. This is especially true of
endpoint agents which are more limited.
• Agents
don't support all platforms.
Data at Rest Enforcement
Once
a policy violation is discovered, the DLP tool can take a variety of actions:
• Alert/Report: create an incident in the central management
server just like a network violation.
• Warn: notify the user via email that they may be in
violation of policy.
• Quarantine/Notify: move the file to the central
management server and leave a text file with instructions on how to request
recovery of the file.
• Quarantine/Encrypt: encrypt the file in place, usually
leaving a plain text file describing how to request decryption.
• Quarantine/Access Control: change access controls to
restrict access to the file.
• Remove/Delete: either transfer the file to the central
server without notification, or just delete it.
•
The
combination of different deployment architectures, discovery techniques, and
enforcement options creates a powerful combination for protecting data at rest
and supporting compliance initiatives. For example, we're starting to see
increasing deployments of CMF to support PCI compliance — more for the ability
to ensure (and report) that no cardholder data is stored in violation of PCI
than to protect email or web traffic.
Data in Use
Network monitoring is
non-intrusive (unless you have to crack SSL) and offers visibility to any
system on the network, managed or unmanaged, server or workstation. It covers
all systems connected to the network. It doesn't protect data when someone
walks out the door with a laptop, and can't even prevent people from copying
data to portable storage like USB drives. To move from a "leak
prevention" solution to a "content protection" solution, products
need to expand not only to stored data, but to the endpoints where data is
used.
Adding an endpoint agent
to a DLP solution not only gives you the ability to discover stored content,
but to potentially protect systems no longer on the network or even protect
data as it's being actively used. While extremely powerful, it has been
problematic to implement. Agents need to perform within the resource
constraints of a standard laptop while maintaining content awareness. This can
be difficult if you have large policies such as, "protect all 10 million
credit card numbers from our database", as opposed to something simpler
like, "protect any credit card number" that will generate false
positives every time an employee visits Amazon.com.
Key Capabilities
Existing products vary
widely in functionality, but we can break out three key capabilities:
1. Monitoring and
enforcement within the network stack: This allows enforcement of network rules
without a network appliance. The product should be able to enforce the same
rules as if the system were on the managed network, as well as separate rules
designed only for use on unmanaged networks.
2. Monitoring and
enforcement within the system kernel: By plugging directly into the operating
system kernel you can monitor user activity, such as copying and pasting
sensitive content. This can also allow products to detect (and block) policy
violations when the user is taking sensitive content and attempting to hide it
from detection, perhaps by encrypting it or modifying source documents.
3. Monitoring and
enforcement within the file system: This allows monitoring and enforcement
based on where data is stored. For example, you can perform local discovery
and/or restrict transfer of sensitive content to unencrypted USB devices.
These options are
simplified, and most early products focus on 1 and 3 to solve the portable
storage problem and protect devices on unmanaged networks. System/kernel
integration is much more complex and there are a variety of approaches to
gaining this functionality.
Use Cases
Endpoint DLP is evolving
to support a few critical use cases:
• Enforcing
network rules off the managed network, or modifying rules for more hostile
networks.
• Restricting
sensitive content from portable storage, including USB drives, CD/DVD drives,
home storage, and devices like smartphones and PDAs.
• Restricting
copy and paste of sensitive content.
• Restricting
applications allowed to use sensitive content — e.g., only allowing
encryption with an approved enterprise solution, not tools downloaded online
that don't allow enterprise data recovery.
• Integration
with Enterprise Digital Rights Management to automatically apply access control
to documents based on the included content.
• Auditing
use of sensitive content for compliance reporting.
Additional Endpoint Capabilities
The following features are
highly desirable when deploying DLP at the endpoint:
• Endpoint
agents and rules should be centrally managed by the same DLP management server
that controls data in motion and data at rest (network and discovery).
• Policy
creation and management should be fully integrated with other DLP policies in a
single interface.
• Incidents
should be reported to, and managed by, a central management server.
• Endpoint
agent should use the same content analysis techniques and rules as the network
servers/appliances.
• Rules
(policies) should adjust based on where the endpoint is located (on or off the
network). When the endpoint is on a managed network with gateway DLP, redundant
local rules should be skipped to improve performance.
• Agent
deployment should integrate with existing enterprise software deployment tools.
• Policy
updates should offer options for secure management via the DLP management
server, or existing enterprise software update tools.
Endpoint Limitations
Realistically, the
performance and storage limitations of the endpoint will restrict the types of
content analysis supported and the number and type of policies that are
enforced locally. For some enterprises this might not matter, depending on the
kinds of policies to be enforced, but in many cases endpoints impose
significant constraints on data in use policies.
Data Loss/ Data Leak technologies category
DLP technologies are broadly divided into two categories – Enterprise DLP and Integrated DLP.Enterprise DLP solutions are comprehensive and packaged in agent software for desktops and servers, physical and virtual appliances for monitoring networks and email traffic, or soft appliances for data discovery.
Integrated DLP is limited to secure web gateways (SWGs), secure email gateways (SEGs), email encryption products, enterprise content management (ECM) platforms, data classification tools, data discovery tools and cloud access security brokers (CASBs).
DLP also can be classified as -
Network-based data loss prevention (DLP) solutions are focused on protecting data while it is in motion. These data loss prevention solutions are installed at the "perimeter" of enterprise networks. They monitor network traffic to detect sensitive data that is being leaked or sent out of the enterprise. Solutions may investigate email traffic, instant messaging, social media interactions, web 2.0 applications, SSL traffic and more. Their analysis engines are looking for violations of predefined information disclosure policies, such as data leaks.
Datacenter or storage-based data loss prevention (DLP) solutions focus on protecting data at rest within an organization’s datacenter infrastructure, such as file servers, SharePoint and databases. These data loss prevention solutions discover where confidential data resides and enable users to determine if it's being stored securely. When confidential information resides on insecure platforms, it is usually an indication of problematic business processes or poorly executed data retention policies.
End-point based data loss prevention (DLP) solutions focus on monitoring PC-based systems (laptops, tablets, POS, etc.) for all actions such as print or transfer to CD/DVD, webmail, social media, USB and more. End-point based solutions are typically event driven in that the agent resident on the end-point is monitoring for specific user actions, such as sending an email, copying a file to a USB, leaking data or printing a file. These solutions can be configured for passive monitoring mode or to actively block specific types of activities.

Application Security and Your Data Loss Prevention Strategy
Use this checklist as a reference tool when making data loss prevention purchase decisions:- Develop clear data loss prevention strategies with concrete requirements before evaluating products.
- Understand the limitations of data leak prevention. As an example, data loss prevention is a data-centric control and does not have any understanding of SQL.
- Applications protect your data. Test the security quality of your applications. Use application security testing as a way of protecting data.
- Create data loss prevention policies and procedures for mobile devices as they interact with sensitive corporate data.
Consideration before DLP deployment
Before you start looking
at any tools, you need to understand why you might need DLP, how you plan on
using it, and the business processes around creating policies and managing
incidents.
1. Identify
business units that need to be involved and create a selection committee: We
tend to include two kinds of business units in the DLP selection process —
content owners with sensitive data to protect, and content protectors with the
responsibility for enforcing controls over the data. Content owners include
those business units that hold and use the data. Content protectors tend to
include departments like Human Resources, IT Security, corporate Legal,
Compliance, and Risk Management. Once you identify the major stakeholders,
you'll want to bring them together for the next few steps.
2. Define
what you want to protect: Start by listing out the kinds of data, as
specifically as possible, that you plan on using DLP to protect. We typically
break content out into three categories — personally identifiable information
(PII, including healthcare, financial, and other data), corporate financial data,
and intellectual property. The first two tend to be more structured and will
drive you towards certain solutions, while IP tends to be less structured, with
different content analysis requirements. Even if you want to protect all kinds
of content, use this process to specify and prioritize, preferably “on paper”.
3. Decide
how you want to protect it and set expectations: In this step you will answer
two key questions. First, in what channels/phases do you want to protect the
data? This is where you decide if you just want basic email monitoring, or if
you want comprehensive data in motion, data at rest, and data in use
protection. You should be extremely specific, listing out major network
channels, data stores, and endpoint requirements. The second question is what
kind of enforcement do you plan on implementing? Monitoring and alerting only?
Email filtering? Automatic encryption? You'll get a little more specific in the
formal requirements later, but you should have a good idea of your expectations
at this point. Also, don't forget that needs change over time, so we recommend
you break requirements into short term (within 6 months of deployment),
mid-term (12-18 months after deployment), and long-term (up to 3 years after
deployment).

4. Outline
process workflow: One of the biggest stumbling blocks for DLP deployments is
failure to prepare the enterprise. In this stage you define your expected
workflows for creating new protection policies and handling incidents involving
insiders and external attackers. Which business units are allowed to request
protection of data? Who is responsible for building the policies? When a policy
is violated, what's the workflow to remediate it? When is HR notified? Legal?
Who handles day-to-day policy violations? Is it a technical security role, or
non-technical, such as a compliance officer? The answers to these kinds of
questions will guide you towards different solutions to meet your workflow
needs.
By the completion of this phase you
should have defined key stakeholders, convened a selection team, prioritized
the data you want to protect, determined where you want to protect it, and
roughed out workflow requirements for building policies and remediating
incidents.
Internal Testing
Make sure you test the products as thoroughly as possible. A few key aspects to test, if you can, are:
• Policy
creation and content analysis. Violate policies and try to evade or overwhelm
the tool to learn where its limits are.
• Email
integration.
• Incident
workflow — Review the working interface with those employees who will be
responsible for enforcement.
• Directory
integration.
• Storage
integration on major platforms to test performance and compatibility for data
at rest protection.
• Endpoint
functionality on your standard image.
• Network
performance — not just bandwidth, but any requirements to integrate the product
on your network and tune it. Do you need to pre-filter traffic? Do you need to
specify port and protocol combinations?
• Network
gateway integration.
• Enforcement
actions.
Conclusion
Data Loss Prevention is a confusing
market, but by understanding the capabilities of DLP tools and using a
structured selection process you can choose an appropriate tool for your
requirements. DLP is a very effective tool for preventing accidental
disclosures and ending bad business processes around the use of sensitive data.
While it offers some protection against malicious attacks, the market is still
a couple years away from stopping knowledgeable bad guys.
DLP products may be adolescent, but
they provide very high value for organizations that plan properly and
understand how to take full advantage of them. Focus on those features that are
most important to you as an organization, paying particular attention to policy
creation and workflow, and work with key business units early in the process.
Most organizations that deploy DLP see significant risk reductions
with few false positives and business interruptions.
Reference:
- 1 https://www.veracode.com/security/guide-data-loss-prevention2 http://whatis.techtarget.com/definition/data-loss-prevention-DLP3 SANS Institute Infosec Reading Room4 https://www.skyhighnetworks.com/cloud-security-blog/how-data-loss-prevention-dlp-technology-works/5 https://en.wikipedia.org/wiki/Data_loss_prevention_software6 http://searchsecurity.techtarget.com/feature/Introduction-to-data-loss-prevention-products7 https://www.devicelock.com/products/8 Understanding and selecting a Data Loss Prevention Solution by Websense Inc. and released in cooperation with the SANS Institute.9 Data Loss Prevention by Prathaben Kanagasingham
1







2 Comments
The perfect data warehousing services provided by your company were developed, effectively tested and builder, which helped in managing the large quantity of transformed data comfortably.
ReplyDeleteCapsule theory is an excellent concept to talk about, but you can't ignore the relation of capsule theories withBig data consulting services.
ReplyDelete